
Beyond Bottlenecks: Strategies to Reduce Contention in High-Load Systems
Struggling with slowdowns under load? How to tackle contention, reduce bottlenecks, and keep your applications running smoothly.

In “Beyond Linear Scaling: How Software Systems Behave Under Load”, I discussed how contention can be a significant obstacle to a system’s scalability. In that article, I provided an example that illustrates how tasks compete for limited shared resources:
[Shared resources] could be computational (e.g., CPU), network-related (e.g., bandwidth), or infrastructure (e.g., a lock on a common table). If one subtask exhausts the shared resource, the other subtasks slow down significantly or may even need to stop and wait until enough resources become available again.
[…] As resources become increasingly saturated, subtasks effectively interfere with each other, and the gain in throughput per additional load unit slows down.
In this article, I want to discuss contention in greater detail and outline several strategies to mitigate its adverse effects. Let’s begin by examining the problem more closely…
What is contention?
In general, contention occurs when multiple processes compete for the same constrained resource or architectural bottleneck. The bottleneck effectively sets the system’s throughput, so overall throughput cannot exceed the bottleneck’s capacity.
Bottlenecks may appear in various forms, including resource limitations or architectural congestion points.
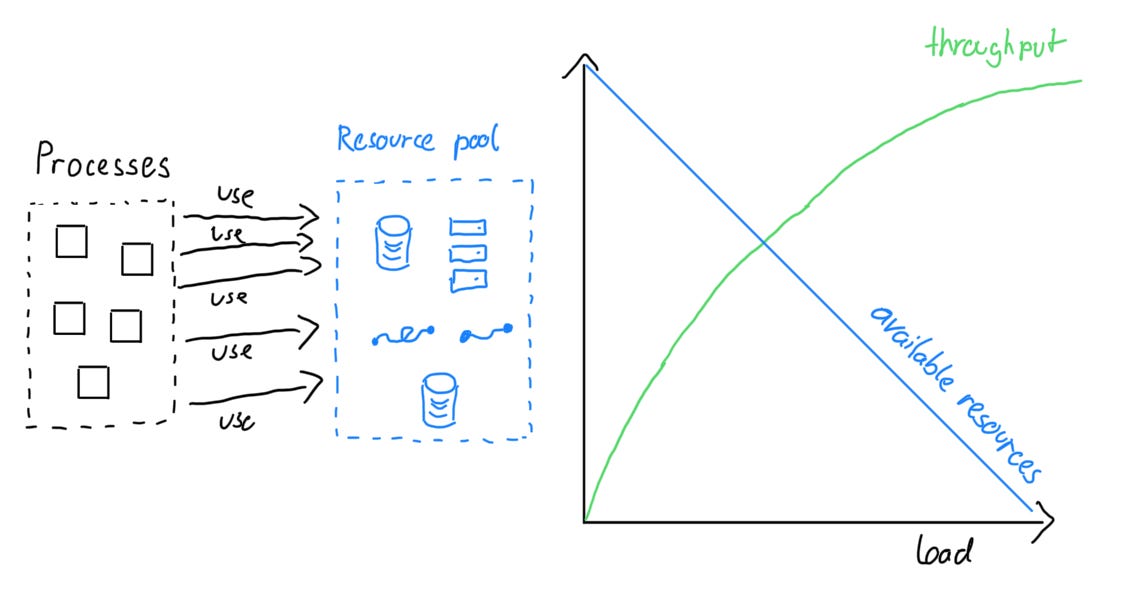
Resource Bottlenecks
When a system (and all its parts) depend on a limited resource pool, contention arises as these resources become depleted. This can be computing power (like CPU), bandwidth on a network, or locks on a common database table. As the load grows, the resource pool shrinks, forcing processes to wait longer and slowing throughput growth. Eventually, resources can be exhausted to the point where no further increase in throughput is possible.
Congestion points
Contention can also occur independently of available resources due to congestion points in the system’s architecture. If a particular bottleneck caps a system’s throughput—for instance, as in the figure below, three units—then no matter how much extra load you add, the maximum throughput remains three.

These congestion points can be services within a process flow or infrastructural elements like message queues. They are common in distributed architectures. Consider multiple services relying on a single downstream service: as concurrency rises, the downstream service becomes overwhelmed, leading to longer response times and overload. This problem is especially severe in systems that rely on synchronous communication since congestion in one component can cascade through the entire system.
There are two broad strategies to lower contention: reducing demands on the bottleneck or increasing its capacity. Let’s discuss both in more detail.
Reducing Demands
Contention arises when bottlenecks face excessive load. One way to address this issue is by lowering those demands. The following sections describe four approaches to accomplish this.
Approach #1: Reduce Resource Bottlenecks by Shifting Resource Usage
If the bottleneck involves a shared resource, consider shifting the workload to another type of resource. For example, you could alleviate a network bandwidth bottleneck by compressing data before sending it. This reduces network demand but increases CPU load due to the additional overhead of executing a compression algorithm. Following this example is a good idea if network bandwidth is constrained but CPU capacity is available more broadly.
Approach #2: Reduce Congestion Points by Replicating State
Let’s examine the following system.

There is substantial communication both between Service 1 and Service 3 and between Service 2 and Service 3. Service 3 holds data that the other two services need. As a result, for every task these services perform, they must query Service 3, making it a congestion point. Once Service 3 becomes overloaded, neither Service 1 nor Service 2 can complete their tasks or fulfill requests.
An alternative approach is to replicate the data. By having Service 1 and Service 2 each store their own copy of the data previously held solely by Service 3, the system now looks as follows:

With this change, Service 1 and Service 2 are less dependent on Service 3. Even if Service 3 fails, both can continue serving requests. Communication between the services is now reduced and focuses primarily on maintaining eventual consistency across the replicated data.
Approach #3: Avoid Unnecessary Calls by Using Backoff and Circuit Breakers
Repeatedly retrying calls to an already overloaded service only puts more burden on it. If every requesting service immediately retries failed requests, the stressed service may eventually crash.
One particular strategy to mitigate this issue is retrying with an exponential backoff. Instead of using a fixed retry interval (e.g., every 100 milliseconds), the requesting service gradually increases the waiting period between retries. By doing so, it reduces the incoming load on the already strained service and gives it a chance to recover.

However, exponential backoff alone is not always sufficient. Consider a scenario with three services: A, B, and C. Service A calls B, and B calls C to fulfill the request. If C becomes unreliable, then B retries with exponential backoff, delaying A’s requests further. As discussed in the section “What is contention?” this is a typical behavior in distributed systems, where failure in one service cascades through large parts of the system.
Circuit breakers help address this issue by halting communication with unresponsive services. They do this by incorporating one of three states:
Closed state
When everything is normal, the circuit breakers remained closed, and all the request passes through to the services as shown below. If the number of failures increases beyond the threshold, the circuit breaker trips and goes into an open state.
Open state
In this state circuit breaker returns an error immediately without even invoking the services. The Circuit breakers move into the half-open state after a timeout period elapses. Usually, it will have a monitoring system where the timeout will be specified.
Half-open state
In this state, the circuit breaker allows a limited number of requests from the service to pass through and invoke the operation. If the requests are successful, then the circuit breaker will go to the closed state. However, if the requests continue to fail, then it goes back to Open state.
Examples of circuit breaker implementations are Hystrix and Sentinel.
Approach #4: Use Asynchronous Processing
Most of the issues described above stem from the synchronous nature of communication. One service invokes another and must wait for its response before continuing its work.
Asynchronous processing can decouple this runtime behavior, for example, by using message queues to buffer requests before they reach a bottleneck. I once worked on a system that needed to handle numerous 3D-rendering requests in parallel, but we could only render four images at a time due to licensing constraints on the rendering engine. To mitigate congestion, we introduced a message queue in front of the engine. Although users still had to wait for their rendering tasks to complete, we could immediately return a meaningful response as soon as we placed their request in the queue.
Increasing Capacity
Besides reducing demands on bottlenecks, you can use the second broad strategy mentioned above: increasing the bottleneck’s throughput.
Approach #5: Optimize Throughput By Performance Tuning
This might seem obvious, but it’s still worth emphasizing. Concentrate your performance optimization efforts on known bottlenecks: refine database queries, add read replicas, or improve code efficiency in areas especially prone to congestion. This provides the best return on investment for your performance-tuning initiatives.
Approach #6: Improve Elasticity By Autoscaling
For addressing bottlenecks, elasticity and efficient resource utilization are crucial. As I wrote in “Reactive Systems: Designing Systems for Multi-Dimensional Change”, systems are elastic if they
[…] can scale up or down in small increments, without manual intervention, to support increasing and decreasing load patterns.
The article also provided the following figure to illustrate the idea of elasticity:

Leverage autoscaling capabilities offered by platforms like Kubernetes or public cloud providers and ensure sufficient resource availability to handle usage spikes.
Approach #7: Improve Elasticity By Splitting Bottlenecks
It is not only autoscaling that enables elasticity but also the system’s architecture. Smaller, more modular, and individually deployable components are easier to scale than large, monolithic deployments with long startup times. I also discussed this in “Reactive Systems: Designing Systems for Multi-Dimensional Change”:
Applications deployed as a single process (deployment monoliths) are harder to scale horizontally due to longer start times, resource intensity, and reliance on session state.
Meanwhile, splitting applications helps them become reactive to changes in load. Two things are important here. First, you can split along functionality and arrive at smaller deployables, which then form the entire system by integrating over network communication (e.g., microservices). Second, you can partition the input range among deployables. Narrower responsibilities (e.g., handling customers only with last names beginning with A-C) reduce the load on individual nodes and make smaller-scale increments possible. Combining both strategies leads to the best outcomes in terms of elasticity, i.e., the ability to scale up and down, on demand, and in small increments.
Conclusion
The approaches in this article are only a subset of all strategies to lower the effects of contention. Because resolving one bottleneck often exposes another, it’s best to iteratively refine your system rather than attempting perfect upfront planning. Identify the most restrictive bottleneck, apply the approaches outlined above, and then move on to the next one. Repeat this process until you’ve reduced system contention to an acceptable level. In a sufficiently complex environment, you may never eliminate contention entirely—but you can make it manageable.